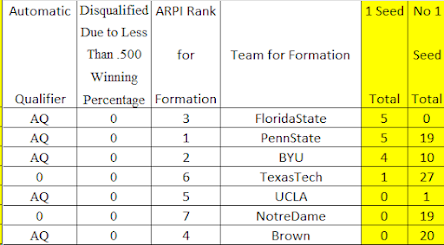
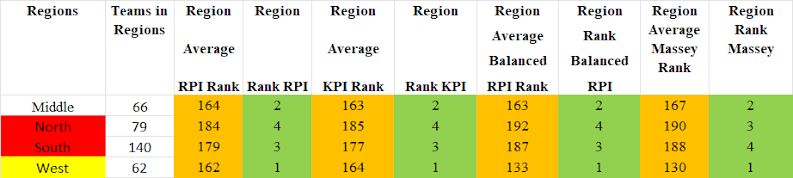
This year, the NCAA is allowing the Women's Soccer Committee to use an additional rating system when it evaluates teams, in addition to the RPI. This is a good thing.
The additional rating system the NCAA is allowing the Committee to use is the KP Index, or KPI. In 2022, the NCAA allowed the Division I Women's Field Hockey Committee to use the KPI to supplement the RPI. I do not know who selected the KPI as the particular additional system for field hockey. I believe the NCAA staff selected it for women's soccer since it already was in use for field hockey.
A big question is whether the KPI is a good supplemental system for DI women's soccer. In my opinion, as I will show below, it is not.
In terms of how KPI ratings match generally with game results, the KPI is fine as a system:

In this table, the ARPI 2015 is the current NCAA RPI. Massey is the Kenneth Massey system, which he has run for many years. The URPI 50 50 SoS Iteration 15 is the Balanced RPI. KPI ratings are available only for years since 2017, and I was able to use Massey ratings only through 2019. For the current NCAA RPI and the Balanced RPI, I was able to use data from 2010 through 2022. I excluded Covid-affected 2020.
The table shows the consistency of ratings with game results. I determined, for each system, the percentage of games in which the team with the higher rating, after adjustment for home field advantage, won the game. I did this using only games that ended in wins or losses since the percentage of tie games differs from year to year and I did not want those differences to deceptively skew the results.
In the percentages, in the Overall column a difference of 0.1% represents a difference of about 3 games per year, out of about 3,000, in which game results match ratings. In the Top 60 column, a difference of 0.1% represents a difference of about 1 game per year, out of about 1,000.
As you can see, the differences in consistency of ratings with game results are not large.
Knowing that for DI women's soccer, game results will be inconsistent with ratings in a significant number of games as the above table shows, one would hope that the inconsistencies would be due either to (1) actual changes in teams' performance over the course of the season or (2) true upsets, which should be randomly distributed. And, conversely, one would hope that the inconsistencies are not due to rating system discrimination against or in favor of teams based on characteristics not related to performance. In particular, one would hope that the inconsistencies are not due to discrimination among teams based on the conferences they are in or the geographic regions in which they are located.
The following table shows whether the four rating systems discriminate among teams based on the conferences they are in:

This table is based on a system that evaluates how well the ratings of teams in a particular group, such as a conference, match with their results against teams from other similar groups, such as other conferences. For a detailed description of the system, see RPI: Measuring the Correlation Between Teams' Ratings and Their Performance.
This particular table deals with the ratings compared to the results of each conference's teams, as a group, in games against teams from other conferences. If the results of a conference are consistent with with what the ratings say they should be, then the performance percentage of the conference is 100%. If the results are better than the ratings say they should be, then the performance percentage is above 100%. If the results are poorer, then the performance percentage is below 100%.
The table looks at conference performance three ways:
In the first four columns with percentages, it looks at the most closely rated 10% of all games. These are the games in which differences between ratings and results are most likely to show up.
In the next four columns, it looks at the most closely rated 20% of all games. I have included these columns to take into account that for the KPI, the 2017 through 2022 data set is relatively small and I was concerned that lack of data might unfairly skew the 10% results.
The final four columns are based on having broken down all of the games into the most closely rated 10%, the second most closely rated 10%, and so on in 10% segments so as to cover all games. The system then calculates the performance percentage for each segment. The final four columns are based on the average performance percentage across all 10 segments. This gives a picture of the net effect of any difficulty the rating system has rating teams from a conference in relation to teams from other conferences.
Using the 10% group as an example, the first column for that group shows the performance percentage of the conference that performs the best in relation to its ratings -- 124.9% for the current NCAA RPI. The next column shows the percentage for the poorest performing conference -- 66.8%. The next column shows the difference -- the Spread -- between those two percentages -- 58.0%. The next column is based on the differences from 100% of all of the conferences, added together -- the Over and Under Total -- 305.9%. The Spread and the Over and Under Total are measurements of how well the system is able to rate teams from the different conferences in relation to each other. The lower the percentages, the better.
As the table shows, the KPI has the same problem as the current NCAA RPI when trying to rate teams from the different conferences in relation to each other. One must be careful not to pay too much attention to the exact KPI numbers due to its limited data set, but the table is clear that it has a conference rating problem. The Balanced RPI, on the other hand, performs much better than either the KPI or the current NCAA RPI.
There is another aspect, of rating teams from the different conferences in relation to each other, that the above tables do not show. This is shown in charts that show how the conference performance percentages relate to conference strength. Here is a chart for the current NCAA RPI.
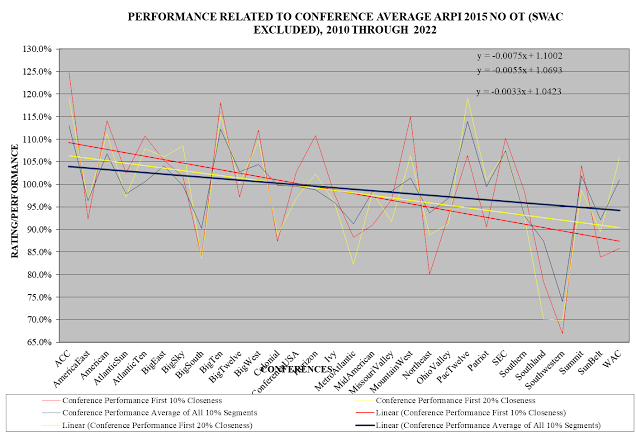
In this chart, the conferences are arranged from left to right in order of the average RPIs of their teams, with the best average RPI on the left and the poorest on the right. (I have not included the Southwestern Athletic Conference because its performance percentage is so poor I believe it would make the trends overly steep.) The red is for performance in the most closely rated 10% of games, the yellow for 20%, and the dark blue for the average across all 10% segments. The straight lines are computer generated trend lines showing the relationship between conference strength and how conferences perform in relation to their ratings. The three formulas in the upper right of the chart are formulas for the three trend lines. The chart shows that under the current NCAA RPI, on average, teams from stronger conferences, in non-conference games, perform better than their ratings say they should and teams from weaker conferences perform more poorly than their ratings say they should. In other words, on average, the current NCAA RPI discriminates against teams from stronger conferences and in favor of teams from weaker conferences.
Here is the same chart, but for the KPI:

You can see that, on average, the KPI discriminates against teams from stronger conferences and in favor of teams from weaker conferences.
Here is the same chart, but for the Balanced RPI:

As you can see, the Balanced RPI has minimal discrimination in relation to conference strength.
The following table summarizes these three charts:

Using the current NCAA RPI and the closest 10% group of games as an example, the first 10% column shows the highest point of the 10% group trend line on the left of the current NCAA RPI chart -- 111.6%, as determined based on the 10% group trend formula. The second 10% column shows the lowest point of the trend line on the right -- 88.1%. The 10% Spread column shows the difference between the performance at the high end and the low end of the trend line -- 23.5%. This difference is a measure of the amount of discrimination against stronger and in favor of weaker conferences. As you can see, looking at the 10%, 20%, and All columns, both the current NCAA RPI and the KPI have significant discrimination; and the Balanced RPI has minimal discrimination and, when looking at all the 10% groups combined, virtually no discrimination.
Here are tables and charts like the ones for conferences, but instead for the geographic regions within which teams are located:





As you can see, both the current NCAA RPI and the KPI have significant discrimination based on geographic regions; and the Balanced RPI has minimal discrimination and, when looking at all the 10% groups combined, virtually no discrimination.
The bottom line is that the KPI is not a good supplemental rating system for DI women's soccer. Rather, it has the same defects as the current NCAA RPI: It discriminates against stronger conferences and geographic regions and in favor of weaker ones.
The NCAA definitely needs to allow the Women's Soccer Committee to use a rating resource in addition to the current NCAA RPI (although discontinuing use of the current NCAA RPI in favor of another system would be better). Using the KPI as the additional resource, however, is not helpful as it only reinforces the current NCAA RPI's discrimination defects. Thus although using another rating system is good, using the KPI as that system is not.