Here are evaluations and comparisons of how the NCAA RPI (which I will refer to as simply the RPI), the KP Index (the KPI), and the Balanced RPI perform as rating systems, after adding the 2023 season's data to the data for prior years. For the Balanced RPI, I have slightly simplified the formula. I did this to make it easier to implement, if the NCAA were to want to use it. The computation method for the Balanced RPI is at the end of this report.
In this report, the RPI and Balanced RPI ratings and ranks are from the 2010 through 2023 seasons, excluding Covid-affected 2020. They are based on game results as though there had been no overtimes, so all games from 2010 through 2021 that went to overtime are treated as ties. This allows us to see how the systems function under the current no overtime rule. For the KPI, ratings and ranks are available only for years since 2017; and from 2017 through 2021 the KPI takes overtime results into account.
At various points in this report, I also will provide data from Kenneth Massey's rating system, which is a well-respected rating system that covers many sports including NCAA women's soccer. The Balanced RPI and Massey ranks of teams in most cases are quite similar, with the differences between the Massey ranks and RPI ranks ordinarily slightly greater than the differences between the Balanced RPI ranks and the RPI ranks. I will provide the Massey data simply as a point of reference and will not discuss it. I have usable data from his system for the years 2007 through 2021, all based on games under the "with overtime" rule, so the data base is not identical to the data base for the other rating systems. Nevertheless, it is useful to see how the RPI, KPI, and Balanced RPI perform as compared to Massey.
How a System Ranks Teams As Compared to How It Ranks Them as Strength of Schedule Contributors
For the RPI and the Balanced RPI, in addition to being able to see how they rank teams, we can see how they rank teams as strength of schedule contributors to their opponents. Ideally, these ranks are the same -- in other words, if you play the #50 team, the strength of schedule part of your rating will credit you with having played the #50 team.
For the KP I, I have not been able to find its computation formula. I assume it computes and uses strength of schedule, including amounts teams contribute to their opponents' strengths of schedule. But I do not know what those amounts are. So, I cannot compare how it ranks teams as compared to how it ranks them as strength of schedule contributors. The same is true for Massey.
Looking at the RPI and the Balanced RPI, the following table shows how team ranks for those systems compare to team ranks as strength of schedule contributors:
As the table shows, the RPI's ranks of teams as strength of schedule contributors differ considerably from the teams' RPI ranks. The average difference between those ranks is almost 30 positions. At least half of all teams have a difference of at least 21 positions. And the largest difference over the years has been 144 positions.
On the other hand, for the Balanced RPI, the average difference between those ranks is only 0.3 positions. At least half of all teams have a difference of no positions. And the largest difference is only 3 positions.
The RPI's differences between RPI ranks and strength of schedule contributor ranks make it possible to trick the rating system. I will give an example from the 2023 season:
UCF RPI Rank 45 Strength of Schedule (SoS) Contributor Rank 93 (Big 12 #7 ranked conference)
Liberty RPI Rank 46 SoS Contributor Rank 10 (Conference USA #17)
Arizona State RPI Rank 47 SoS Contributor Rank 84 (Pac 12 #4)
Thus although the RPI Ranks say these teams were essentially equal, their contributions to the strength of schedule components of their opponents' ratings were very different. Essentially, Liberty was a very desirable opponent from an RPI perspective and UCF and Arizona State were not.
Here are some similar examples from 2023:
Michigan RPI Rank 50 SoS Contributor Rank 123 (Big 10 #3)
Lamar RPI Rank 51 SoS Contributor Rank 15 (Southland #26)
LSU RPI Rank 52 SoS Contributor Rank 122 (SEC #1)
**************************************************
Pepperdine RPI Rank 40 SoS Contributor Rank 69 (West Coast #8)
Towson RPI Rank 41 SoS Contributor Rank 12 (Colonial #14)
Providence RPI Rank 42 SoS Contributor Rank 60 (Big East #6)
In each example, from a strength of schedule contribution perspective, all of the teams from the strong conferences were undesirable opponents. On the other hand, all of the teams from the weaker conferences were desirable opponents. Why does this happen? As compared to comparably ranked teams from stronger conferences, teams from the weaker conferences' tend to have better winning percentages but poorer strengths of schedule. When the RPI formula evaluates teams as strength of schedule contributors, it evaluates them almost entirely (80%) based on their winning percentages. Thus if you have two teams with RPI Ranks about the same, with one from a weaker conference and the other from a strong conference, you ordinarily want to play the one from the weaker conference. Even though the two teams' RPI ranks are about the same, the team from the weaker conference will give a better contribution to your RPI strength of schedule. This is not always the case, but most of the time it is.
Because of this RPI phenomenon, smart scheduling can trick the RPI, making the RPI think you have played a stronger schedule than you really have played. This is one of the reasons basketball stopped using the RPI.
The Balanced RPI does not have this defect. Teams' Balanced RPI ranks match their Balanced RPI ranks as strength of schedule contributors. The above teams' 2023 ranks are examples:
UCF Balanced RPI Rank 38 Balanced RPI SoS Contributor Rank 38
Liberty Balanced RPI Rank 67 Balanced RPI SoS Contributor Rank 67
Arizona State Balanced RPI Rank 41 Balanced RPI SoS Contributor Rank 41
Michigan Balanced RPI Rank 33 Balanced RPI SoS Contributor Rank 33
Lamar Balanced RPI Rank 105 Balanced RPI SoS Contributor Rank 105
LSU Balanced RPI Rank 59 Balanced RPI SoS Contributor Rank 59
Pepperdine Balanced RPI Rank 36 Balanced RPI SoS Contributor Rank 36
Towson Balanced RPI Rank 69 Balanced RPI SoS Contributor Rank 68
Providence Balanced RPI Rank 48 Balanced RPI SoS Contributor Rank 47
In fact, I designed the computation method for the Balanced RPI specifically to accomplish this. Thus it is not possible to trick the Balanced RPI.
This means that if the NCAA were to shift to the Balanced RPI, it would make coaches' non-conference scheduling much easier. With the RPI, coaches with NCAA Tournament aspirations must take care to pick and choose the right teams to play, in the different rank areas they want for their opponents. In each rank area, some opponents will be good from an RPI perspective and other opponents will be bad. With the Balanced RPI, this will not be the case. Any team in a rank area will be just as good an opponent to play as any other team in that rank area.
To put it differently, from an RPI perspective, what you see for an opponent (RPI rank) often is not what you will get (RPI strength of schedule contribution rank). For the Balanced RPI, however, what you see always is what you will get.
Is the System Able to Rank Teams from a Conference Properly in Relation to Teams from Other Conferences?
The following tables show how well the systems do when rating teams from a conference in relation to teams from other conferences. In the tables, a conference "performance percentage" of 100% means that on average the conference's teams, in their games against teams from other conferences, perform in accord with their ratings. A performance percentage above 100% means that the conference's teams perform better than their ratings say they should -- they are underrated. A performance percentage below 100% means the conference's teams perform more poorly than their ratings say they should -- they are overrated.
One should not expect any rating system to produce ratings and ranks that exactly match all game results. Rather, when looking at all of the conferences, one should expect a range of conference performance percentages with some above 100% and some below, but with all hopefully within a narrow range. When evaluating and comparing rating systems from a conference perspective, this raises an important question: How narrow is a system's range of conference performance percentages, with smaller ranges being preferable.
a. Most Underrated and Overrated Conferences.
This table evaluates how the systems perform when looking at the most closely rated 10% of games. These are the games in which results inconsistent with ratings are most likely to show up.
Looking at the RPI row, the High column shows the performance percentage -- 122.0% -- of the conference that most outperformed its ratings in non-conference games. The Low column shows the performance percentage -- 68.1%, or 31.9% below 100% -- of the conference that most underperformed its ratings. One could say that the High conference performed 22.0% better than its ratings say it should and the low conference performed 31.9% more poorly. The Spread column is the sum of these two numbers: 53.9%. This Spread -- or range -- is one measure of how the RPI performs from a conference perspective: the lower the number, the better the performance.
Looking at the KPI, its Spread is 72.7%. This is worse than the RPI.
Looking at the Balanced RPI, its spread is 41.8%. This is the best of the three systems.
As a note, however, about the KPI: This method of analysis looks at relatively narrow slices of data, which creates the possibility of misleading results when the overall data sample is small. For the RPI and Balanced RPI, where the analysis is based on all games from 2010 through 2023, the data sample is large. For the KPI, the data sample is smaller, limited to games played since 2017.
This table is the same as the previous one, but for the most closely rated 20% of games. It simply is a larger data set than the previous one. Again, the Balanced RPI does the best, the RPI is significantly poorer, and the KPI is the worst.
This table is similar, but slightly different. The games are sliced into the most closely rated 10%, the second most closely rated 10%, the third most closely rated 10%, and so on through all the games. Each 10% slice has a conference performance percentage for each rating system. In the table, the columns show the averages across all the slices.
Thus for the RPI, the conference with the High average performance percentage across all the slices has a performance percentage of 113.7%. Effectively, its results are better than its ratings say they should be in 13.7% more games than would be normal. The Low conference is at 87.8%. The Spread between the two is 25.9%.
For the KPI, the Spread is 28.8%.
For the Balanced RPI, the Spread is 7.0%.
Thus for these measures of rating system performance, the Balanced RPI is much better than the RPI and KPI at rating teams from a conference in relation to teams from other conferences. And of the three systems, the KPI is the worst.
b. Amount of Underrating and Overrating for All Conferences. The preceding tables looked at the most underrated and overrated conferences. The following tables look at the combined amount of underrating and overrating for all conferences by asking: By what amount does a system miss a 100% performance percentage for each conference; and what do the those amounts for all conferences add up to?
In this table, the Over and Under column shows, for the most closely rated 10% of games, the total amount by which all conferences' performance percentages miss 100%. The Balanced RPI performs the best, missing by 220.0%, followed by the RPI at 291.0% and the KPI at 437.0%.
For the most closely rated 20% of games, again the Balanced RPI performs the best, missing by 164.6%, with the RPI at 257.6% and the KPI at 394.2%.
Looking at the average across all the 10% slices, the Balanced RPI again is the best at 40.5%, much better than the RPI at 148.5% and the KPI at 160.2%.
c. Bias in Relation to Conference Strength. The above two sets of tables show how the systems do generally at rating teams from a conference in relation to teams from other conferences. The following three charts, one for each system, show how the conference misses of the "perfect" 100% performance percentage relate to conference strength:
This chart is for the RPI. It has the conferences arranged in order of their average RPI ratings over the 2010 to 2023 period, ranging from the conference with the best average RPI rating on the left to the conference with the poorest rating on the right. The vertical axis is for the conference performance percentage over this period.
The straight lines on the chart are computer-generated trend lines that paint a picture of the pattern the RPI has in rating teams from the different conferences in relation to each other. The orange line is for the most closely rated 10% of games, the red line for the most closely rated 20%, and the blue line for the average across all the 10% slices. Although there are variations from conference to conference, the gist of the chart is clear: The stronger the conference, the greater the extent to which the conference's teams overperform in relation to their ratings -- in other words, the more the RPI underrates them; and the weaker the conference, the greater the extent of its underperformance -- in other words, the more the RPI overrates them.
Note: In this and other charts I will show, I have not included the Southwestern Athletic Conference (SWAC). I have excluded SWAC because its performance percentage is far poorer than that of any other conference. If I were to include it, the downward angle of the trend lines would be even sharper, in my opinion overstating the amount of the rating systems' discrimination.
In the upper right hand corner of the chart, you can see three formulas. These are for the trend lines, with the closest 10% of games trend line formula at the top, followed by the 20% formula and then the "all 10% slices" formula.
The next chart is for the KPI:
The next chart is for the Balanced RPI:
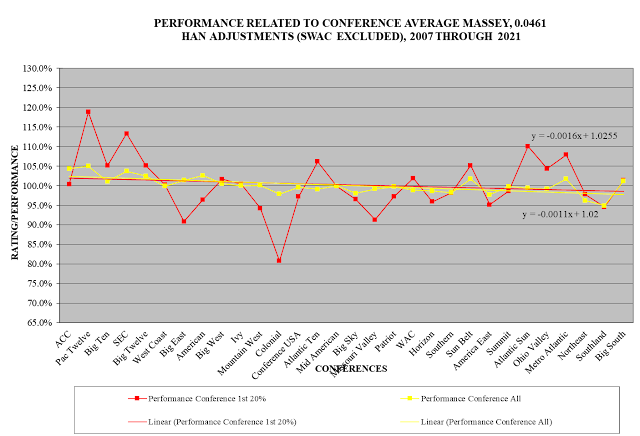
The next chart is for Massey. This chart shows results for only the most closely rated 20% of games and all the 10% slices of games.
Using the trend line formulas, it is possible to quantify the amount by which each rating system tends to underrate the strong end of the conference spectrum, on the left, as compared to overrating the weak end of the spectrum, on the right. The gap between those two amounts is a representation of the extent of the system's discrimination in relation to conference strength.
The following table shows the extent of the systems' discrimination, for the most closely rated 10% of games:
As you can see, for the most closely rated 10% of games, the strongest conference tends to perform 10.9% better than its ratings say it should whereas the weakest conference tends to perform 11.4% more poorly. The Spread between the two is 22.3%, which is a measure of the RPI's discrimination in relation to conference strength.
For the KPI, the Spread is 19.1%.
For the Balanced RPI, the Spread is -2.0%.
The following table is for the most closely rated 20% of games:
Here is the table for the average across all the 10% slices:
As the tables show, the RPI and KPI produce ratings that discriminate in relation to conference strength, discriminating against teams from stronger conferences and in favor of teams from weaker conferences. For the Balanced RPI, however, the Trend Spreads are low enough to indicate no effective discrimination.
The RPI's overall failure to properly rate teams from a conference in relation to teams from other conferences, and its pattern of discrimination against stronger and in favor of weaker conferences, appear to be a result of its defective method of calculating teams' strength of schedule contributions to their opponents. This is why the Balanced RPI, with its corrected method of computing strength of schedule contributions, also remedies the RPI's improper rating of a conference's teams in relation to teams from other conferences.
As for the KPI, since its strength of schedule contribution calculation method is not available, it is not possible directly to say that is the source of its conference problem. Nevertheless, the similarities between the RPI's conference problem and the KPI's conference problem suggest the KPI may have a strength of schedule problem similar to the RPI's.
Is the System Able to Rank Teams from a Geographic Region Properly in Relation to Teams from the Other Geographic Regions?
Based on a study of the geographic areas within which teams from each state play either the majority or the plurality of their games, the country has four regions. These are not the same as the geographic regions the NCAA uses for some organizational purposes. Rather, they represent where teams from the states tend to play their games.
The following material shows how the rating systems perform when rating teams from a region in relation to teams from other regions. It uses the same method as used above for conferences.
a. Most Underrated and Overrated Regions. The following tables show how well the systems do when rating teams from a region in relation to teams from other regions.
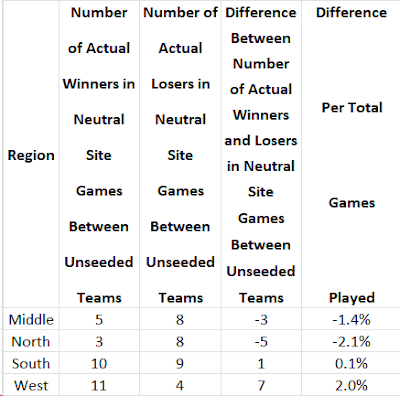
As you can see, for the most closely rated 10% of games, the RPI and KPI both have a large Spread between the best-performing region and the poorest. The Balanced RPI, on the other hand, has a small Spread.
The pattern is similar for the most closely rated 20% of games.
For the average across the 10% slices, the pattern again is the same.
Looking at all three tables, the RPI and KPI are not able to properly rate teams from the different regions in relation to each other. For practical purposes, however, the Balanced RPI, for this measure, does a good job properly rating them in relation to each other.
b. Amount of Underrating and Overrating for All Regions.
This shows the combined amounts by which each rating system misses a "perfect" 100% performance percentage for each region, using the different slices of games. As you can see, the RPI and KPI both miss by large amounts. The Balanced RPI misses, however, are small and for practical purposes mean the Balanced RPI, for this measure, properly rates teams from the regions in relation to teams from other regions.
c. Bias in Relation to Region Strength.
This chart is for the RPI. Along the horizontal axis, the regions are in order from the region with the best average rating on the left to the poorest on the right. According to the trend lines, the RPI discriminates against stronger regions and in favor of weaker ones. On the other hand, the ups and downs of the chart suggest that other factors also may be at play.
For the KPI, the chart is very similar to the one for the RPI.
For the Balanced RPI, on the other hand, the chart shows minimal, if any, discrimination in relation to region strength.
Here is the chart for Massey:
Use of the trend line formulas from the charts produces the following table:
As you can see, for each of the slices of games as well as for all the slices combined, both the RPI and KPI have significant discrimination in relation to region strength. The Balanced RPI, on the other hand, for all practical purposes does not discriminate.
Similar to the case with conferences, the RPI's overall failure to properly rate teams from a region in relation to teams from other regions, and its pattern of discrimination against stronger and in favor of weaker regions, appear to be a result of its defective method of calculating teams' strength of schedule contributions to their opponents. This is why the Balanced RPI, with its corrected method of computing strength of schedule contributions, also remedies the RPI's improper rating of a region's teams in relation to teams from other regions.
From a Simple Game Results Perspective, How Consistent Are a System's Ratings with Game Results?
The final two evaluation and comparison factors look simply at the correlations between systems' ratings and game results (without regard to conference or region).
This chart is based on calculations that ask the following question: After adjusting for home field advantage, how often does the team with the better rating win, tie, and lose?
Using the RPI as an example, and remembering that for the RPI this is based on all games played since 2010 with the game results as they would have been with no overtimes, the higher rated team won 65.3% of the time, tied 21.1%, and lost 13.6%.
I have a highlight shadow for the KPI numbers because its 2017 through 2021 underlying data include the results of overtime games and thus are not good for an apples to apples comparison to the RPI and Balanced RPI numbers, which include far more ties.
For the Balanced RPI, the higher rated team won 65.8% of the time, tied 21.1%, and lost 13.0%. (The numbers do not add up to 100% due to rounding.)
Thus the Balanced RPI does better than the RPI by 0.5%. This is not a large difference. Each 0.1% represents 3 games out of a roughly 3,000 game season. Thus the Balanced RPI does better by matching game results for about 15 more games per year, out of 3,000 games.
To get a better comparison of how the KPI performs in relation to the RPI and Balanced RPI, the column on the right of the above table disregards ties and asks: Of the games that were won or lost, what proportion did the better rated team win? As you can see from that column, the Balanced RPI ratings were the most consistent with results for those games, followed by the RPI and then the KPI.
This final table is for games that involved at least one Top 60 team. For this table, it is important to note that since each system has its own set of Top 60 teams, the numbers of ties are different. This makes the Disregarding Ties column the most important indicator of how a system does for this subset of teams. As you can see, the Balanced RPI does the best when disregarding ties, followed by the RPI and then the KPI.
These differences again are not large. For this subset of games, a difference of 0.1% represents ratings matching game results for 1 more game per year out of roughly 1,000 games in the subset.
Final Comments
As the above analysis shows, there is a big disconnect between teams' RPI ranks and their RPI ranks as strength of schedule contributors. This makes it possible to trick the RPI by employing certain scheduling tactics and, as a result, makes non-conference scheduling difficult for teams with NCAA Tournament aspirations. The Balanced RPI does not have this problem and thus would make non-conference scheduling much easier.
The RPI's strength of schedule defect causes the RPI to be poor at properly rating teams from conferences in relation to teams from other conferences and teams from regions in relation to teams from other regions. By eliminating that defect, the Balanced RPI also eliminates the RPI's conferences and regions defect.
The KPI is similar to the RPI in being poor at properly rating teams from conferences and regions in relation to teams from other conferences and regions. This suggests that it likewise may have a strength of schedule measurement defect, but it is not possible to verify this due to a lack of information about how the KPI computes strength of schedule.
The Balanced RPI ratings are slightly more consistent with game results than are the RPI and KPI ratings, but the differences in consistency are small. From a rating system perspective, this is not surprising. In rating systems comparisons, the range of correlation rate differences between ratings and results ordinarily is small. Thus in comparing systems, the question is not what those correlation results are but rather how the cases where "ratings do not match results" are distributed. In an ideal system, the cases are distributed randomly so that over time they affect all teams more or less equally. The problem with the RPI and KPI is that the "ratings do not match results" cases are not distributed randomly. Rather, they affect teams from different conferences and different regions in unequal ways and in addition have a specific pattern of discriminating against teams from stronger conferences and regions and in favor of teams from weaker conferences and regions. The Balanced RPI, however, does not have this problem and instead appears to have the desired random distribution of misses so that over time no conference's or region's teams are favored or disfavored.
Computing the Balanced RPI
RPI Element 1 is the NCAA's Winning Percentage
RPI Element 1 is the NCAA's Opponents' Winning Percentage
RPI Element 3 is the NCAA's Opponents' Opponents' Winning Percentage
Computation 1:
URPI 50 50 SoS:
(RPI_Element_1+(RPI_Element_2*1.4)+(RPI_Element_3*2.4))/4
[Note: This is the same as the NCAA's basic RPI formula except that the Element 2 and Element 3 multipliers are 1.4 and 2.4 respectively rather than the NCAA's 2 and 1. The effect of this is to change the effective weights of the three elements from the NCAA's 50%-40%-10% to 50%-25%-25%.]
Computation 2:
URPI 50 50 SoS Iteration 2:
(RPI_Element_1+4.5*(Opponents_Average_URPI_50_50_SoS-0.135))/4
[Note: This treats the first calculation of a team's RPI rating (from Computation 1) as its contribution to its opponents' strengths of schedule. The 4.5 multiplier applied to the Opponents' Average URPI 50 50 SoS is to give RPI Element 1 (Winning Percentage) and the Opponents' Average URPI 50 50 SoS (Strength of Schedule) each a 50% effective weight. The .135 subtracted towards the end of the equation simply is a centering adjustment to keep the ratings within a range we are used to seeing for RPI ratings.]
Computation 3:
URPI 50 50 SoS Iteration 3:
(RPI_Element_1+4*(Opponents_Average_URPI_50_50_SoS_Iteration_2-0.135))/4
[Note: This equation is the basic format for each of the remaining computation steps. It treats the result of the preceding computation as the strength of schedule component of the RPI. The 4 multiplier applied to the Opponents' Average URPI 50 50 SoS Iteration 2 is to give RPI Element 1 (Winning Percentage) and the Opponents' Average URPI 50 50 SoS Iteration 2 (Strength of Schedule) each a 50% effective weight. The .135 centering adjustment is to keep the resulting ratings within a range we are used to seeing. The 4 multiplier and .135 centering adjustment are constants for all the remaining calculation steps.]
Computation 4:
URPI 50 50 SoS Iteration 4:
(RPI_Element_1+4*(Opponents_Average_URPI_50_50_SoS_Iteration_3-0.135))/4
Computations 5 through 14:
URPI 50 50 SoS Iterations 5 through 14:
These computations follow the same pattern as Computations 3 and 4.
Computation 15:
Balanced RPI:
(RPI_Element_1+4*(Opponents_Average_URPI_50_50_SoS_Iteration_14-0.135))/4
[Note: For the period from 2010 through 2023, on average this produces effective weights for Winning Percentage and Strength of Schedule of exactly 50% each.]